Úspešnosť systémov na podporu odhaľovania plagiátov závisí od viacerých faktorov – je to hlavne kvalita algoritmu na odhaľovanie podobností textov v ich variantoch (copy & paste, parafrázy, nahradzovanie slov synonymami. Keď hovoríme o odhaľovaní podobností textov, máme na mysli aj odhaľovanie prekladov z iných jazykov. Úspešnosť systému podporuje prístup do početných kvalitných úložísk elektronických dokumentov.
V medzinárodnej štúdii z roku 2020 Testing of Support Tools for Plagiarism Detection sa hodnotí pätnásť systémov na podporu odhaľovania plagiátov naprieč ôsmimi jazykmi (angličtina, čeština, lotyština, nemčina, slovenčina, španielčina, taliančina a turečtina) z hľadiska efektívnosti vyhľadávania podobností a z hľadiska ich použiteľnosti. Konštatuje sa, že systémy majú ešte ďaleko do dokonalosti v odhaľovaní synoným, v odhaľovaní parafráz a hlavne v odhaľovaní translačného plagiátorstva.
Systémy najdlhšie etablované na trhu majú s veľkou pravdepodobnosťou prístup do početnejšej množiny elektronických úložísk dokumentov ako systémy novšie. To predstavuje pre nich značnú výhodu. Skúsme hodnotiť systémy na základe kvality vyhľadávania podobností v kontrolovaných dokumentov len v prostredí Wikipédie, do ktorej majú všetky systémy prístup. Tým odfiltrujeme výhody systémov s prístupom do početných elektronických úložísk a sústredíme sa na samotnú kvalitu detekčných algoritmov.
Venujme sa najprv tej najľahšej úlohe z medzinárodného testovania – nájdenie textu z Wikipédie vloženého do kontrolovaného dokumentu metódou kopíruj & vlož (copy & paste). Ako sa s tým vyrovnali testované systémy? Predpokladal som, že systémy nebudú mať s touto úlohou problémy, ale výsledky (za osem jazykov) to nepotvrdili. Maximálne hodnotenie (5 bodov) dosiahli len Unicheck a Urkund. Do horného kvartilu sa dostali okrem dvoch už menovaných ešte aj StrikePlagiarism a Turnitin. Hodnoty nižšie ako 5 bodov naznačujú určité problémy v technológii vyhľadávania zhodných textov v kontrolovaných dokumentoch.
Ako vyzerá nájdenie textu alebo jeho časti z Wikipédie vloženého do dokumentu spôsobom, že sa niektoré slová nahradili ich synonymami? Žiadny systém nedosiahol maximálnu hodnotu 5-tich bodov (maximum 4,56). Špičku – (horný kvartil) tvoria systémy Urkund (91,2% z maxima), PlagiarismCheck, Turnitin, Copyscape, StrikePlagiarism.
Teraz skúmajme úspešnosť systémov v nachádzaní parafrázovaného textu z Wikipédie. Žiadny systém nedosiahol maximálnu hodnotu 5-tich bodov (maximum 2,88) a ich bodové hodnotenie naznačuje, že s nájdením parafráz majú systémy značné problémy. V hornom kvartile sú systémy Urkund (57,6% z maxima), PlagiarismCheck, PlagScan, Akademia.
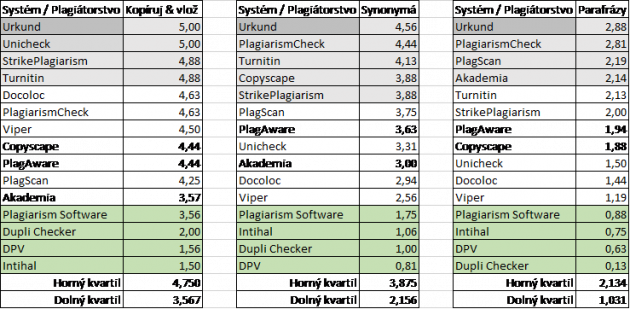
Jednoznačným lídrom vo vyhľadávaní vo Wikipédii v týchto troch spôsobov plagiátorstva (tabuľka vyššie) je Urkund, i keď pri parafrázach vôbec neoslnil. V hornom kvartile sa dvakrát vyskytli Strike Plagiarism, Turnitin a PlagiarismCheck. Stabilnými outsidermi sa stali Plagiarism Software, Dupli Checker, DPV a Intihal.
Pokiaľ ide o translačné plagiátorstvo, tam majú systémy najväčšie rezervy. Jeho detekcia je na nízkej úrovni, snáď sa zlepší v blízkej budúcnosti. Systém Akademia dosiahol hodnotu 1,5 bodu (30% z maxima) – výrazne sa líšil od ostatných systémov, ktorých celkové hodnotenie sa pohybovalo v intervale od 0 do 0,3 bodu. Hodnota 0 bola dominujúcou hodnotou pre jednotlivé systémy naprieč jazykmi. Výsledky sa týkajú detekcie prekladov z angličtiny do testovaných jazykov.
Systém Akadémia je zaujímavý tým, že práve pri odhaľovaní tých zložitejších úloh (odhaľovanie parafráz, odhaľovanie prekladov z angličtiny) sa dostal medzi špičku.
Súvisiace články:
Hodnotenie systémov na podporu odhaľovania plagiátov
Výsledky analýzy efektívnosti nástrojov na podporu odhaľovania plagiátov




















V málo dušiach vzklíčia jadierka zo stromu... ...
Zvedavosť Evy nenápadne priviedla Adama k... ...
+++ Aj ja tu mám jeden plagiát. Biblický. ... ...
Celá debata | RSS tejto debaty